
CAS
# CAS
# 1、CAS简介
CAS(Compare-And-Swap),直译为比较交换。 CAS是一种用于多线程编程的原子操作。主要用于无锁算法和无锁数据结构的实现。
# CAS 在Java中常用于以下几种场景:
- 实现无锁数据结构:如无锁队列(ConcurrentLinkedQueue)等。
- 线程安全计数器:如实现原子性递增操作(原子类)。
- 并发容器:如 Java 中的 java.util.concurrent 包中的许多类都使用了 CAS 操作。
# CAS的设计思想和具体操作步骤:
CAS的思想非常简单,当在并发环境下需要更新某个共享变量的值时,先查询这个变量的当前值和预期值进行比较,如果相同才更新为新的值,如果不同就什么都不做。它的核心思想在于提供了一种在多线程环境下安全更新共享数据的方式,而无需使用传统的互斥锁。
CAS 操作涉及三个参数: 一个内存位置 P,一个预期值 E, 和一个新值 N。
CAS具体操作步骤如下:
- ①、读取内存位置P处的当前值。
- ②、将当前值与预期值E进行比较。
- ③、如果当前值等于预期值E,则将新值N写入内存位置P处,并返回 true 表示操作成功。
- ④、如果当前值不等于预期值E,则不做任何更改,并返回 false 表示操作失败。
CAS操作的优点:
- ①、无锁操作:CAS 是一种无锁操作,这意味着它不需要线程互斥锁,可以避免因锁竞争而导致的性能瓶颈。
- ②、简单、高效:CAS 的实现相对简单易于理解。由于没有锁的开销,CAS 可以在多线程环境中实现高效的同步。
# 2、CAS的局限性
每项技术都有其优点和局限性,没有哪一项技术能够完美适用于所有场景。CAS也不例外。
CAS有些非常经典的问题:
①、ABA 问题:如果一个值从 A 变成 B,然后又变回 A,CAS 操作无法检测到这种变化。这种问题可以通过使用额外的版本号或标签来解决。 比如JDK提供的AtomicStampedReference类就可以用来解决ABA问题。
②、繁忙等待:如果 CAS 操作反复失败,可能会导致线程处于繁忙等待状态,消耗 CPU 资源,Java中CAS+自旋操作就是个典型的例子。这个应该算是自旋锁的局限性吧,不过自旋锁大多数是通过CAS操作来实现的,算CAS的局限性也没毛病。
③、同时操作多个共享变量无法保证原子性: 如果在自旋锁中同时操作多个共享变量,CAS没办法保证同时对多个共享变量操作的原子性。不过JDK提供了AtomicReference类来保证引用对象之间的原子性,就可以把多个变量放在一个对象里来进行CAS操作。
# 3、CAS的底层原理
处理器层面
CAS操作通常由处理器直接支持,作为一组特殊的机器指令,这些指令能够在一个不可分割的操作中完成比较和交换。这样的指令确保了操作的原子性,即整个过程要么全部完成,要么完全不执行,不会被其他操作打断。
处理器的原子指令操作
X86架构: CMPXCHG(Compare and Exchange)指令是最常见的CAS指令。 它接受三个参数:目标内存地址、预期旧值、新值。如果目标内存地址处的值等于预期旧值,CMPXCHG会将新值写入该地址,并返回旧值;如果不匹配,则返回当前值且不做任何更改。
ARM架构: 使用LDXR(Load Exclusive Read)和STXR(Store Exclusive)指令对来实现CAS。首先使用LDXR读取值并标记位置为独占,然后进行比较,如果在此期间位置未被其他线程修改,则使用STXR交换值。
# Unsafe类
# 1、Unsafe类简介
Unsafe类在之前 AQS详解 (opens new window) 和 LockSupport详解 (opens new window)中都有提到。
Unsafe听名字就知道这个类不安全,它是Java平台提供的一个内部类,位于sun.misc包下,它允许Java代码直接访问和操作底层内存,执行一些通常被认为是不安全的操作。
Unsafe类提供了对直接内存访问、原子操作、线程同步等底层功能的支持,这使得它成为实现高性能数据结构和并发控制机制的关键工具。
# 2、如何使用 Unsafe类
看下Unsafe类 的构造方法:
私有构造方法,说明无法通过new 关键字来创建对象。
private Unsafe() {
}
再看下类结构:
public final class Unsafe
final修饰也无法继承。
看下Unsafe 有没有提供其他方法来获取 Unsafe 实例。
private static final Unsafe theUnsafe;
@CallerSensitive
public static Unsafe getUnsafe() {
Class var0 = Reflection.getCallerClass();
if (!VM.isSystemDomainLoader(var0.getClassLoader())) {
throw new SecurityException("Unsafe");
} else {
return theUnsafe;
}
}
就是他了, 调用这个方法试下再说。
import sun.misc.Unsafe;
public class TestA {
public static void main(String[] args) throws InterruptedException {
Unsafe unsafe = Unsafe.getUnsafe();
}
}
不出意外的话,意外就要发生了~
抛异常了:
Exception in thread "main" java.lang.SecurityException: Unsafe
at sun.misc.Unsafe.getUnsafe(Unsafe.java:90)
at TestA.main(TestA.java:9)
这是因为Unsafe.getUnsafe() 方法只能在由引导类加载器(bootstrap class loader)加载的类中使用。我们自己的类TestA是由系统类加载器(Application ClassLoader)加载的所以会抛异常。
# 两种方式可以绕过这种安全检查获取到Unsafe的实例。
# ①、让bootstrap class loader加载自己的类
上面例子就是让让bootstrap class loader加载TestA
具体步骤:
利用JVM参数 -Xbootclasspath/a
-Xbootclasspath/a 是一个 JVM 选项,用于将指定的 JAR 文件或目录追加到引导类加载器的搜索路径中。
直接把TestA类的目录加到这个参数后面
-Xbootclasspath/a:"C:\Users\Administrator\Desktop\TestJavaSE\out\production\TestJavaSE"
注意:这个路径是我电脑上的路径(注意修改成自己电脑上的路径),而且路径下面要是javac编译后的.class文件 或者 jar文件才行。
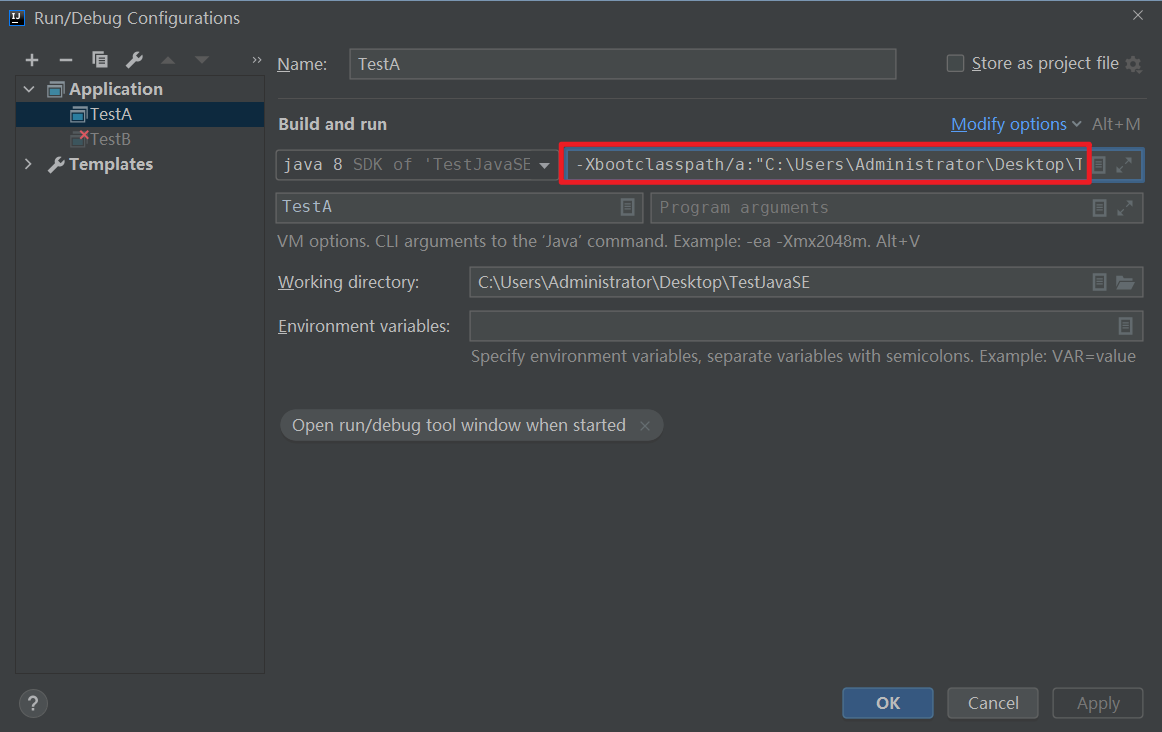
当添加了 -Xbootclasspath/a:"C:\Users\Administrator\Desktop\TestJavaSE\out\production\TestJavaSE" 启动参数后就能成功获取Unsafe实例了。
# ②、通过反射
Unsafe类有个类属性private static final Unsafe theUnsafe;利用反射获取这个属性。
import sun.misc.Unsafe;
import java.lang.reflect.Field;
public class TestA {
public static void main(String[] args) throws InterruptedException {
Unsafe unsafe = reflectGetUnsafe();
System.out.println(unsafe);
}
private static Unsafe reflectGetUnsafe() {
try {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
return (Unsafe) field.get(null);
} catch (Exception e) {
System.out.println("获取失败");
return null;
}
}
}
# 3、Unsafe类的功能
下面功能点特意按照抽象程度排了个序,越往下看越抽象~
# ①、CAS操作
正好对应上面说的CAS。
Unsafe类提供的CAS方法如下:
/*
* @param o 要更新字段的对象
* @param offset 对象内字段的内存偏移量
* @param expected 预期的字段值
* @param args 要设置的新值
* @return 如果字段值被成功更新,则返回 true;否则返回 false
*/
public final native boolean compareAndSwapObject(Object o, long offset, Object expected, Object args);
public final native boolean compareAndSwapInt(Object o, long offset, int expected, int args);
public final native boolean compareAndSwapLong(Object o, long offset, long expected, long args);
拿compareAndSwapInt举个例子:
# 实现一个基于CAS的计数器:
import sun.misc.Unsafe;
import java.lang.reflect.Field;
public class TestA {
public static void main(String[] args) {
CasCounter counter = new CasCounter();
// 创建多个线程来并发地递增计数器
for (int i = 0; i < 10; i++) {
new Thread(() -> {
for (int j = 0; j < 1000; j++) {
counter.increment();
}
}).start();
}
// 等待所有线程完成
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 输出最后的计数值
System.out.println("Final count: " + counter.getCount());
}
}
class CasCounter {
private volatile int count;
private static final Unsafe unsafe;
private static final long countOffset;
static {
try {
// 通过反射获取Unsafe实例
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
unsafe = (Unsafe) field.get(null);
// 获取count字段的内存偏移量
countOffset = unsafe.objectFieldOffset(CasCounter.class.getDeclaredField("count"));
} catch (Exception e) {
throw new Error(e);
}
}
public void increment() {
while (true) {
// 获取当前值
int current = unsafe.getIntVolatile(this, countOffset);
// 当前值+1
int next = current + 1;
// CAS设置值
if (unsafe.compareAndSwapInt(this, countOffset, current, next)) {
break;
}
}
}
public int getCount() {
return count;
}
}
# ②、线程调度
/**
* 唤醒指定的线程,使其退出等待状态。
*
* @param var1 要被唤醒的线程对象
*/
public native void unpark(Object var1);
/**
* 使当前线程进入等待状态,直到调用unpark方法或等待超时。
*
* @param var1 表示是否使用绝对时间还是相对时间:
* 如果为true,表示使用绝对时间,var2为时间的绝对值;
* 如果为false,表示使用相对时间,var2为等待时间的相对值(从当前时间开始算起)。
* @param var2 时间参数:
* 当var1为true时,var2表示绝对时间(单位为纳秒,从1970年1月1日0时0分0秒开始算起);
* 当var1为false时,var2表示相对时间(单位为纳秒,表示从当前时间开始等待的时间)。
*/
public native void park(boolean var1, long var2);
LocKSupport类提供的线程挂起和唤醒方法就是利用的上面两个方法。
具体参考另一篇博客 LockSupport详解 (opens new window)
# ③、对象操作
# a. 基础数据类型操作
Unsafe类允许直接操作基础数据类型的内存,包括读写整数、浮点数等。
例如:
getInt(Object o, long offset): 获取对象o在内存偏移量offset处的int值。
putInt(Object o, long offset, int x): 设置对象o在内存偏移量offset处的int值为x。
类似的方法还有getLong、putLong、getFloat、putFloat等。
# b.获取和设置对象字段值:
getObject(Object o, long offset): 获取对象o在内存偏移量offset处的对象引用。
putObject(Object o, long offset, Object x): 设置对象o在内存偏移量offset处的对象引用为x。
# c. 有序写入
有序写入(或延迟写入)操作是一种轻量级的写操作,比volatile写操作效率高,但是仅保证写入操作的顺序性,而不保证可见性。
public native void putOrderedObject(Object o, long offset, Object x);
public native void putOrderedInt(Object o, long offset, int x);
public native void putOrderedLong(Object o, long offset, long x);
# d. volatile读写
volatile读写操作: volatile写入操作确保写入操作立即对其他线程可见,保证了内存可见性。
getIntVolatile(Object o, long offset): 获取对象o在内存偏移量offset处的volatile int值。
putIntVolatile(Object o, long offset, int x): 设置对象o在内存偏移量offset处的volatile int值为x。
类似的方法还有getLongVolatile、putLongVolatile、getObjectVolatile、putObjectVolatile等。
# ④、数组操作
// 返回数组中第一个元素的内存偏移量,即数组头部的偏移量。
public native int arrayBaseOffset(Class<?> var1);
// 返回数组元素之间的内存偏移量增量
public native int arrayIndexScale(Class<?> var1);
示例:
import sun.misc.Unsafe;
import java.lang.reflect.Field;
public class TestA {
public static void main(String[] args) {
int[] array = {0, 1, 2, 3};
// 使用Unsafe获取第三个数组元素的值
// (注意如果 数组元素的偏移量超过了数组的内存地址范围 会返回0)
long offset3 = intArrayBaseOffset + 2L * intArrayIndexScale;
int i = unsafe.getInt(array, offset3);
System.out.println(i);
// 使用Unsafe设置 数组的第4个元素 为100
long offset4 = intArrayBaseOffset + 3L * intArrayIndexScale;
unsafe.putInt(array, offset4, 100);
System.out.println(array[3]);
}
private static final Unsafe unsafe;
private static final int intArrayBaseOffset;
private static final int intArrayIndexScale;
static {
try {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
unsafe = (Unsafe) field.get(null);
// 获取数组第一个元素的偏移量
intArrayBaseOffset = unsafe.arrayBaseOffset(int[].class);
// 获取数组元素间的偏移地址增量
intArrayIndexScale = unsafe.arrayIndexScale(int[].class);
} catch (Exception e) {
throw new Error(e);
}
}
}
# ⑤、内存操作
Unsafe类提供了一组直接操作内存的方法,可以分配、调整、设置、拷贝和释放内存。这些方法允许开发者绕过Java的内存管理机制,直接操作原生内存。
1. 分配新的本地空间
方法:public native long allocateMemory(long bytes)
功能:分配指定大小的内存空间,并返回内存地址。
参数:bytes - 要分配的内存大小,以字节为单位。
返回值:分配的内存地址。
long address = unsafe.allocateMemory(1024); // 分配1KB的内存
2. 重新调整内存空间的大小
方法:public native long reallocateMemory(long address, long bytes)
功能:调整指定地址的内存大小。如果内存地址无效,则行为未定义。
参数:address - 内存地址,bytes - 新的内存大小。
返回值:新的内存地址。
long newAddress = unsafe.reallocateMemory(address, 2048); // 调整内存大小到2KB
3. 将内存设置为指定值
方法:public native void setMemory(Object o, long offset, long bytes, byte value)
功能:将指定对象的内存区域设置为指定值。可以操作整个对象或对象的一部分。
参数:o - 要设置内存的对象,offset - 内存起始偏移,bytes - 要设置的字节数,value - 设置的值。
unsafe.setMemory(null, address, 1024, (byte) 0); // 将1KB的内存设置为0
4. 内存拷贝 方法:public native void copyMemory(Object srcBase, long srcOffset, Object destBase, long destOffset, long bytes) 功能:将源地址的内存区域拷贝到目标地址的内存区域。 参数:srcBase - 源对象,srcOffset - 源内存起始偏移,destBase - 目标对象,destOffset - 目标内存起始偏移,bytes - 拷贝的字节数。
unsafe.copyMemory(srcObject, srcOffset, destObject, destOffset, 1024); // 拷贝1KB的内存
5. 清除内存 方法:public native void freeMemory(long address) 功能:释放指定地址的内存。该地址必须是通过allocateMemory或reallocateMemory方法分配的。 参数:address - 要释放的内存地址。
unsafe.freeMemory(address); // 释放内存
注意:
使用Unsafe类直接操作内存时,内存分配的空间属于堆外内存(off-heap memory),这部分内存不受JVM的垃圾回收机制管理。因此,开发者需要手动释放这些内存,以避免内存泄漏。
在实际开发中,通常采用以下方式来确保内存被正确释放:
在 try 块中执行内存操作:执行可能会抛出异常的操作,如内存分配和使用。
在 finally 块中释放内存:确保无论操作是否成功,最终都会执行内存释放,以避免内存泄漏。
在Java的NIO中还提供了DirectByteBuffer类来用于直接操作堆外内存。直接缓冲区(Direct ByteBuffer)是为了避免 Java 堆的内存复制开销,直接在操作系统的物理内存中分配空间,从而提高性能。
DirectByteBuffer的内存分配、使用和释放的逻辑主要就是依赖于 Unsafe 类提供的堆外内存 API。这部分后续计划在整理Netty框架的时候再细说。
# ⑥、Class操作
1. 获取字段偏移量
objectFieldOffset
public native long objectFieldOffset(Field field)
功能:获取实例字段的内存偏移量。
参数:Field field - 需要获取偏移量的实例字段。
返回值:实例字段的内存偏移量,用于后续的内存操作。
public native long staticFieldOffset(Field field)
功能:获取静态字段的内存偏移量。
参数:Field field - 需要获取偏移量的静态字段。
返回值:静态字段的内存偏移量。
public native Object staticFieldBase(Field field)
功能:获取包含指定静态字段的基对象。
参数:Field field - 需要获取基对象的静态字段。
返回值:包含指定静态字段的基对象。
2.其他相关方法 defineClass: 动态定义一个类。 allocateInstance: 创建类的实例,但不调用其构造函数。
说到这个 创建类的实例,但不调用其构造函数,让我想到之前看过的一个问题,有哪些方式可以获取单例类的多个不同对象?
用Unsafe的allocateInstance就是一种方式。
破解单例类的代码示例:
import sun.misc.Unsafe;
import java.lang.reflect.Field;
public class TestA {
private static final Unsafe unsafe;
static {
try {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
unsafe = (Unsafe) field.get(null);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) throws InstantiationException {
Singleton singleton1 = (Singleton) unsafe.allocateInstance(Singleton.class);
Singleton singleton2 = (Singleton) unsafe.allocateInstance(Singleton.class);
System.out.println(singleton1);
System.out.println(singleton2);
}
}
class Singleton {
//声明为 private 避免调用默认构造方法创建对象
private Singleton() {}
// 声明为 private 表明静态内部该类只能在该 Singleton 类中被访问
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
public static Singleton getUniqueInstance() {
return SingletonHolder.INSTANCE;
}
}
# ⑦、内存屏障
内存屏障在 volatile关键字详解 (opens new window) 中有详细说到。
//禁止读操作重排序
public native void loadFence();
//禁止写操作重排序
public native void storeFence();
//禁止读、写操作重排序
public native void fullFence();
内存屏障方法和volatile关键字区别:
内存屏障方法提供了对读和写操作重排序的更细粒度的控制。可以分别控制读操作和写操作的重排序,而volatile关键字是一种更高层次的抽象,自动处理了读写的内存屏障。因为volatile对所有读写操作都插入了屏障,因此在某些情况下可能会带来性能上的开销。内存屏障方法则允许开发者根据需要插入适当的屏障,从而在某些场景下获得更好的性能。
# ⑧、系统相关
// 返回本地指针(内存地址)的大小
public native int addressSize();
// 获取系统的内存页面大小(以字节为单位)
public native int pageSize();
补充知识点:
本地指针(内存地址):
地址大小(address size)指的是一个指针在内存中所占用的字节数。指针是用来存储内存地址的,因此地址大小与系统的内存寻址能力直接相关。
常见的地址大小有:
32位系统:指针大小为4字节(32位)。
64位系统:指针大小为8字节(64位)。
内存页面的定义和作用: 基本单位:
内存页面是内存管理的最小单位。操作系统将物理内存划分为大小固定的块,每一块称为一个页面(Page)。
常见的页面大小是4KB,但也有其他大小,如2MB和1GB的巨页(Huge Page)。
页面表(Page Table):
操作系统通过页面表将虚拟内存地址映射到物理内存地址。每个进程都有自己的虚拟地址空间,通过页面表转换为实际的物理地址。
页面表项(Page Table Entry, PTE)存储了虚拟地址到物理地址的映射信息。
分页机制(Paging):
分页机制允许操作系统使用虚拟内存技术,使得程序能够使用比实际物理内存更多的内存。
当程序访问不在物理内存中的页面时,会触发页面缺失(Page Fault),操作系统会将所需页面从磁盘交换区加载到物理内存中。
内存页面的大小
页面大小通常是固定的,但可以根据系统配置进行调整。常见的页面大小有:
4KB: 大多数系统的标准页面大小。
2MB: 大页(Huge Page),适用于大内存需求的应用,减少了页面表项的数量,提高了TLB(Translation Lookaside Buffer)命中率。
1GB: 超大页(Gigantic Page),进一步减少了页面表项的数量,但通常只在特定应用和操作系统配置下使用。
代码示例:
import sun.misc.Unsafe;
import java.lang.reflect.Field;
public class TestA {
private static final Unsafe unsafe;
static {
try {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
unsafe = (Unsafe) field.get(null);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) throws InstantiationException {
System.out.println(unsafe.addressSize());
System.out.println(unsafe.pageSize());
}
}
运行结果:
8
4096
说明电脑的内存地址是8B, 内存页面的大小为4MB
# 4、Unsafe类的JVM层面实现
OpenJDK8 的HotSpot JVM源码中关于Unsafe类的实现,具体在 unsafe.cpp源码中体现。
unsafe.cpp 文件包含了 Unsafe 类中本地方法的实现。
unsafe.cpp 文件的特性:
底层访问: unsafe.cpp 中的方法提供了对底层内存和对象的直接访问,可以进行高效的内存操作和对象操作。
高性能: 由于这些方法是本地方法(JNI),它们避免了许多 Java 语言级别的检查和限制,从而可以更高效地执行。
高风险: 由于这些方法可以绕过 Java 的安全模型,直接操作内存和对象,它们可能会导致程序崩溃或其他严重问题。因此,它们通常只在高性能库和框架中使用,不推荐普通开发者使用。
补充知识点:
JNI:
Java Native Interface (JNI) 是 Java 提供的一种编程框架,使 Java 代码能够与使用其他编程语言(如 C 和 C++)编写的应用程序和库进行交互。通过 JNI,Java 程序可以调用本地(Native)方法,也可以被本地代码调用。
JNI 的主要用途
与已有库的集成:可以调用已有的用 C/C++ 编写的库,而不需要重新用 Java 实现这些功能。
系统级编程:可以调用底层的系统 API,而这些 API 可能在 Java 标准库中没有对应的实现。
性能优化:在某些性能关键的场景下,可以用 C/C++ 编写高效的代码,然后通过 JNI 调用这些代码。
JNI 的基本工作原理
Java 代码声明本地方法:在 Java 类中声明本地方法(native method),但不提供其实现。
生成头文件:使用 javah 工具生成对应的 C/C++ 头文件。
实现本地方法:在 C/C++ 代码中实现这些本地方法。
加载本地库:在 Java 代码中使用 System.loadLibrary 方法加载包含本地方法实现的动态库。
Java Native Interface (JNI) 是 Java 提供的一种编程框架,使 Java 代码能够与使用其他编程语言(如 C 和 C++)编写的应用程序和库进行交互。通过 JNI,Java 程序可以调用本地(Native)方法,也可以被本地代码调用。
JNI 的主要用途 与已有库的集成:可以调用已有的用 C/C++ 编写的库,而不需要重新用 Java 实现这些功能。 系统级编程:可以调用底层的系统 API,而这些 API 可能在 Java 标准库中没有对应的实现。 性能优化:在某些性能关键的场景下,可以用 C/C++ 编写高效的代码,然后通过 JNI 调用这些代码。 JNI 的基本工作原理 Java 代码声明本地方法:在 Java 类中声明本地方法(native method),但不提供其实现。 生成头文件:使用 javah 工具生成对应的 C/C++ 头文件。 实现本地方法:在 C/C++ 代码中实现这些本地方法。 加载本地库:在 Java 代码中使用 System.loadLibrary 方法加载包含本地方法实现的动态库。
使用 JNI 的步骤:
JNI的具体使用不再赘述了,感兴趣的可以自己Google或者百度了解下。
# 总结:
Unsafe 类提供了许多强大的底层操作,但由于其不安全性和复杂性,应该谨慎使用,通常仅在性能关键的场景下由有经验的开发者使用。对于一般的开发任务,推荐使用更安全和高级的 Java 标准库功能。
上面对于Unsafe的一些描述主要是为了了解JDK提供的一些标准类是如何利用Unsafe来实现其功能的。 对于Unsafe本身的使用应当非常谨慎。
# Java原子类
# 1、原子类概述
Java的原子类位于 java.util.concurrent.atomic包下。
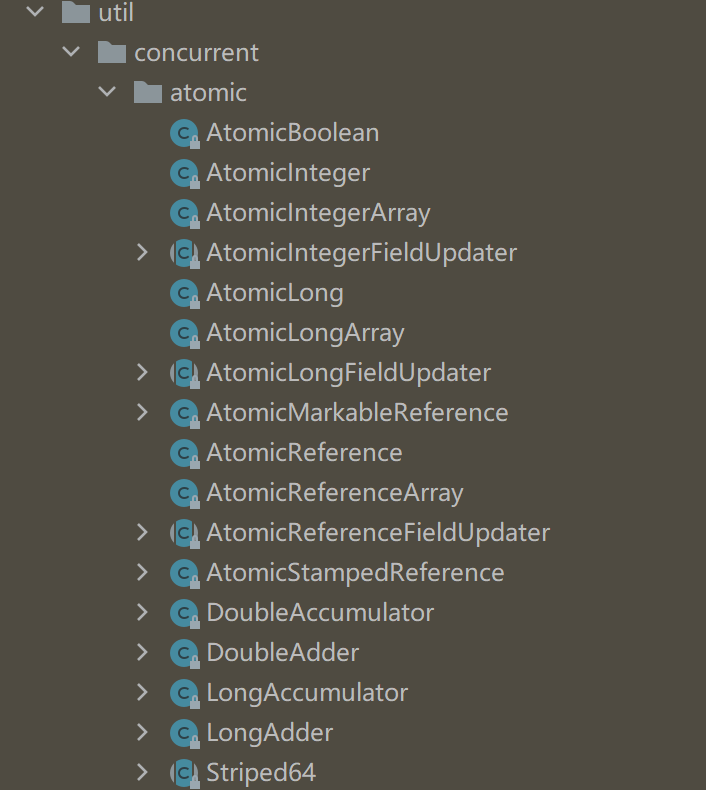
| 类名称 | 功能描述 |
|---|---|
AtomicBoolean | 提供了一个可以原子更新的 boolean 值。 |
AtomicInteger | 提供了一个可以原子更新的 int 值。 |
AtomicIntegerArray | 提供了可以原子更新的 int 数组。 |
AtomicIntegerFieldUpdater | 用于原子地更新指定类的 int 字段。 |
AtomicLong | 提供了一个可以原子更新的 long 值。 |
AtomicLongArray | 提供了可以原子更新的 long 数组。 |
AtomicLongFieldUpdater | 用于原子地更新指定类的 long 字段。 |
AtomicMarkableReference | 提供了一个可以原子更新的对象引用,并带有一个标记位。 |
AtomicReference | 提供了一个可以原子更新的对象引用。 |
AtomicReferenceArray | 提供了可以原子更新的对象引用数组。 |
AtomicReferenceFieldUpdater | 用于原子地更新指定类的对象引用字段。 |
AtomicStampedReference | 提供了一个可以原子更新的对象引用,并带有一个整数标记,可以用于解决 ABA 问题。 |
DoubleAccumulator | 支持原子性的更新和检索双精度浮点值的类,带有自定义的累加功能。 |
DoubleAdder | 支持原子性的更新和检索双精度浮点值的类,适用于高并发场景。 |
LongAccumulator | 支持原子性的更新和检索长整型值的类,带有自定义的累加功能。 |
LongAdder | 支持原子性的更新和检索长整型值的类,适用于高并发场景。 |
Striped64 | 支持动态扩展的高效多线程更新的基础类,DoubleAdder 和 LongAdder 基于此类实现。 |
原子类提供了原子操作,即不可分割的操作。这意味着原子操作在执行过程中不会被线程调度机制中断,因此线程间的操作是安全的。原子类通常是围绕一个单一的变量进行设计的,提供了一些基本的原子操作(如读取、写入、更新等)。
原子类通过提供一些高效的操作(比如CAS)来避免使用传统的同步机制(如synchronized关键字)所带来的性能开销。
# 2、原子类常用操作分析
# 原子类核心操作
- 读取和写入:如get()和set()方法。
- 原子更新:如compareAndSet(expectedValue, newValue),只有在当前值等于预期值时才更新为新值。
- 增减操作:如incrementAndGet()和decrementAndGet(),这些方法提供了在更新值时的原子操作。
# AtomicInteger简单使用示例
做线程安全的累加器:
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
public class TestA {
private static AtomicInteger atomicInteger = new AtomicInteger();
public static void main(String[] args) throws InstantiationException {
for (int i = 0; i < 100; i++) {
new Thread(() -> {
atomicInteger.incrementAndGet();
}).start();
}
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(atomicInteger.get());
}
}
incrementAndGet方法详解:
该方法实现对 int 值的原子性递增操作
public final int incrementAndGet() {
// 首先,unsafe.getAndAddInt(this, valueOffset, 1) 会原子地将 valueOffset 指向的位置的值增加 1,
// 并返回增加前的旧值。
// 然后在旧值的基础上加 1,得到递增后的新值,并将其作为方法的返回值。
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
# AtomicReference简单使用示例
利用AtomicReference提供的CAS方法更新对象属性:
import java.util.concurrent.atomic.AtomicReference;
public class TestA {
// 使用 AtomicReference 管理 Dog 对象
private final AtomicReference<Dog> dogRef;
public TestA(Dog initialDog) {
this.dogRef = new AtomicReference<>(initialDog);
}
// 获取当前狗对象
public Dog getDog() {
return dogRef.get();
}
// 更新狗的名字
public boolean updateDogName(String newName) {
while (true) {
Dog currentDog = dogRef.get();
Dog newDog = new Dog(newName);
if (dogRef.compareAndSet(currentDog, newDog)) {
return true;
}
}
}
public static void main(String[] args) {
// 创建一个初始狗对象
Dog dog = new Dog("秀逗");
TestA example = new TestA(dog);
Thread t1 = new Thread(() -> {
for (int i = 1; i <= 5; i++) {
example.updateDogName("秀逗" + i);
}
}, "t1");
Thread t2 = new Thread(() -> {
for (int i = 1; i <= 5; i++) {
example.updateDogName("秀逗" + i);
}
}, "t2");
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Final dog: " + example.getDog());
}
}
// 定义一个 Dog 类
class Dog {
private String name;
public Dog(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Dog{name='" + name + "'}";
}
}
# 3、利用原子类解决CAS的ABA问题
# AtomicStampedReference
AtomicStampedReference 通过增加一个时间戳(stamp)来解决ABA问题。这个时间戳可以被视为对值的版本控制,确保即使值经过多次变化回到原来的值,时间戳也会发生变化。适用于需要版本控制的场景。
代码示例:
import java.util.concurrent.atomic.AtomicStampedReference;
public class TestA {
private static AtomicStampedReference<Integer> atomicStampedRef =
new AtomicStampedReference<>(100, 0);
public static void main(String[] args) {
final int[] stampHolder = new int[1];
Thread t1 = new Thread(() -> {
int stamp = atomicStampedRef.getStamp();
Integer reference = atomicStampedRef.getReference();
System.out.println("线程t1 获取初始值: " + reference + ", Stamp: " + stamp);
try {
Thread.sleep(1000);
} catch (Exception e) {
}
// 把值设置为110 前提是值没有动过
boolean isSuccess = atomicStampedRef.compareAndSet(reference, reference + 10, stamp, stamp + 1);
System.out.println("t1 - CAS 操作结果: " + isSuccess);
});
Thread t2 = new Thread(() -> {
try {
Thread.sleep(200);
} catch (Exception e) {
}
int stamp = atomicStampedRef.getStamp();
Integer reference = atomicStampedRef.getReference();
boolean isSuccess = atomicStampedRef.compareAndSet(reference, reference + 10, stamp, stamp + 1);
System.out.println("t2 - 第一次 CAS 操作结果: " + isSuccess + " 值:" + atomicStampedRef.getReference() + " Stamp:" + atomicStampedRef.getStamp());
stamp = atomicStampedRef.getStamp();
reference = atomicStampedRef.getReference();
isSuccess = atomicStampedRef.compareAndSet(reference, reference - 10, stamp, stamp + 1);
System.out.println("t2 - 第二次 CAS 操作结果: " + isSuccess + " 值:" + atomicStampedRef.getReference() + " Stamp:" + atomicStampedRef.getStamp());
});
t1.start();
t2.start();
}
}
结果:
线程t1 获取初始值: 100, Stamp: 0
t2 - 第一次 CAS 操作结果: true 值:110 Stamp:1
t2 - 第二次 CAS 操作结果: true 值:100 Stamp:2
t1 - CAS 操作结果: false
# AtomicMarkableReference
AtomicMarkableReference 可以通过一个布尔标记(mark)来解决ABA问题。这个布尔标记可以标识值是否被修改过。适用于简单的标记修改场景。
import java.util.concurrent.atomic.AtomicMarkableReference;
public class TestA {
private static AtomicMarkableReference<Integer> atomicMarkableRef =
new AtomicMarkableReference<>(100, false);
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
boolean[] markHolder = new boolean[1];
Integer reference = atomicMarkableRef.get(markHolder);
System.out.println("线程t1 获取初始值: " + reference + ", Mark: " + markHolder[0]);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
boolean isSuccess = atomicMarkableRef.compareAndSet(reference, reference + 10, markHolder[0], !markHolder[0]);
System.out.println("t1 - CAS 操作结果: " + isSuccess);
});
Thread t2 = new Thread(() -> {
try {
Thread.sleep(200);
} catch (InterruptedException e) {
}
boolean[] markHolder = new boolean[1];
Integer reference = atomicMarkableRef.get(markHolder);
boolean isSuccess = atomicMarkableRef.compareAndSet(reference, reference + 10, markHolder[0], !markHolder[0]);
System.out.println("t2 - 第一次 CAS 操作结果: " + isSuccess + " 值:" + atomicMarkableRef.get(markHolder) + " Mark:" + markHolder[0]);
});
t1.start();
t2.start();
}
}
运行结果:
线程t1 获取初始值: 100, Mark: false
t2 - 第一次 CAS 操作结果: true 值:110 Mark:true
t1 - CAS 操作结果: false
这样做有个缺陷,如果t2再改一次 把值和标记再改成100,和false,那么t1的CAS操作仍然会成功,AtomicMarkableReference只适合简单的一次修改场景。
# 4、DoubleAdder、LongAdder的设计思想
DoubleAdder 和 LongAdder 是 JDK8 引入的两个新类,用于解决并发编程中的高并发计数问题。它们是 java.util.concurrent.atomic 包中的一部分,主要设计思想是减少线程争用来提高并发性能。
在高并发环境下,多个线程同时更新一个共享变量(如计数器)时,可能会导致严重的性能问题。传统的 AtomicInteger 和 AtomicLong 类使用 CAS(Compare-And-Swap)操作来实现线程安全的更新,但在高并发情况下,多个线程同时竞争更新同一个变量,会导致大量的 CAS 失败重试,过多的CPU空转会降低系统性能。
LongAdder 和 DoubleAdder 的设计思想是将计数器的值分散到多个变量中(称为 cells),每个线程尽量更新不同的变量,从而减少竞争。最终的计数值是所有变量的总和。 这种分散热点来减少竞争的思想非常像JDK7中分段锁机制。 在需要获取最终计数值时,遍历所有的 cells,将它们的值相加,得到最终结果。
使用示例:
import java.util.concurrent.atomic.LongAdder;
public class TestA {
public static void main(String[] args) {
LongAdder longAdder = new LongAdder();
// 创建多个线程来增加计数器
Runnable task = () -> {
for (int i = 0; i < 1000; i++) {
longAdder.increment();
}
};
Thread[] threads = new Thread[10];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(task);
threads[i].start();
}
// 等待所有线程完成
for (int i = 0; i < threads.length; i++) {
try {
threads[i].join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 打印最终计数值
System.out.println("最终计数值: " + longAdder.sum());
}
}
运行结果:
最终计数值: 10000
# LongAdder的 increment方法详解
LongAdder 的 increment 方法通过内部的 add 方法实现。其核心思想是将计数操作分散到多个变量(cells)中,从而减少线程争用。
// increment 方法只是简单地调用 add 方法,并将参数设置为 1
public void increment() {
add(1L);
}
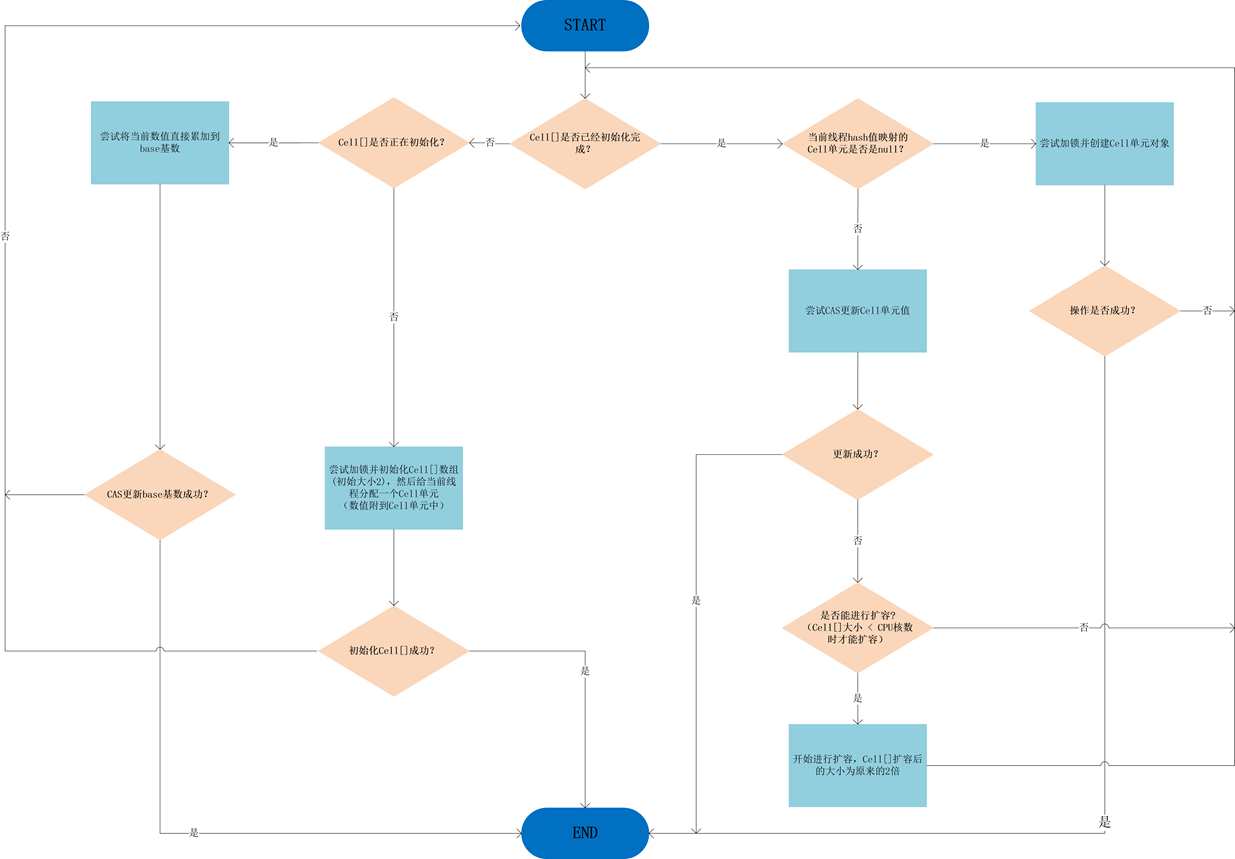
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
if ((as = cells) != null || !casBase(b = base, b + x)) {
// 如果 cells 数组不为空,或者 CAS 更新 base 失败
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
// 如果 cells 数组为空,或者根据线程的 probe 值计算的索引处的 cell 为空,
// 或者 CAS 更新 cell 的值失败,则进入 longAccumulate 方法进行复杂处理
longAccumulate(x, null, uncontended);
}
}
final void longAccumulate(long x, LongBinaryOperator fn, boolean wasUncontended) {
int h;
// 获取当前线程的 probe 值,如果为 0 则初始化
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current(); // 强制初始化
h = getProbe();
wasUncontended = true;
}
boolean collide = false; // 标记是否发生冲突
for (;;) {
Cell[] as; Cell a; int n; long v;
if ((as = cells) != null && (n = as.length) > 0) {
// 如果 cells 数组已经初始化并且长度大于 0
if ((a = as[(n - 1) & h]) == null) {
// 如果当前 probe 值对应的 cell 为空,尝试创建新 cell
if (cellsBusy == 0) { // 如果 cells 没有被其他线程初始化
Cell r = new Cell(x); // 乐观地创建新 cell
if (cellsBusy == 0 && casCellsBusy()) {
// 如果成功获取 cells 的锁
boolean created = false;
try {
// 再次检查 cells 并插入新 cell
Cell[] rs; int m, j;
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0; // 释放锁
}
if (created) // 如果 cell 成功插入,退出循环
break;
continue; // 如果没有成功插入,重新尝试
}
}
collide = false; // 未发生冲突,重置标记
}
else if (!wasUncontended) { // 如果 CAS 已经失败
wasUncontended = true; // 设置未发生冲突,继续重试
}
else if (a.cas(v = a.value, ((fn == null) ? v + x : fn.applyAsLong(v, x)))) {
// 如果成功更新 cell 的值,退出循环
break;
}
else if (n >= NCPU || cells != as) {
collide = false; // 如果 cells 已达到最大容量或 cells 被其他线程修改,重置标记
}
else if (!collide) {
collide = true; // 如果未发生冲突,设置冲突标记
}
else if (cellsBusy == 0 && casCellsBusy()) {
// 如果已经发生冲突,并且成功获取 cells 的锁,尝试扩展 cells
try {
if (cells == as) { // 再次检查 cells 数组
Cell[] rs = new Cell[n << 1]; // 扩展 cells 容量
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs; // 更新 cells 引用
}
} finally {
cellsBusy = 0; // 释放锁
}
collide = false; // 重置冲突标记
continue; // 重新尝试更新
}
h = advanceProbe(h); // 更新 probe 值,避免一直更新同一个 cell
}
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
// 如果 cells 数组未初始化,并且成功获取 cells 的锁,初始化 cells
boolean init = false;
try {
if (cells == as) {
Cell[] rs = new Cell[2]; // 初始大小为 2 的 cells 数组
rs[h & 1] = new Cell(x); // 将值插入到 cells 数组中
cells = rs; // 更新 cells 引用
init = true;
}
} finally {
cellsBusy = 0; // 释放锁
}
if (init) // 如果成功初始化,退出循环
break;
}
else if (casBase(v = base, ((fn == null) ? v + x : fn.applyAsLong(v, x)))) {
// 如果所有尝试都失败,回退到更新 base 变量
break;
}
}
}
add方法执行流程图:
图片来源https://www.skjava.com/series/article/1618088484 (opens new window)
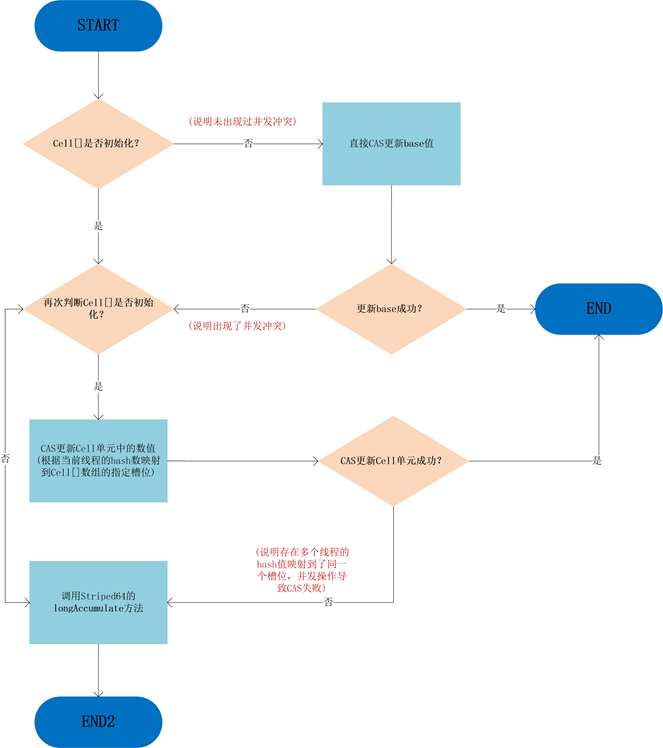
longAccumulate方法执行流程图:
图片来源https://www.skjava.com/series/article/1618088484 (opens new window)
# sum方法是否能得到精确值:
LongAdder 设计的初衷是为了在高并发环境下提供更好的性能,因此,它通过分散计数减少竞争。然而,这种设计也带来一个问题:在某些特定的瞬间调用 sum 方法时,由于并发修改,可能会得到稍微不一致的结果。但总的来说,sum 方法是线程安全的,并且能够在绝大多数情况下提供精确的计数值。
在高并发场景下,多个线程可能会同时修改不同的 Cell 或 base,导致 sum 方法计算时的值稍微滞后于实际值。然而,这种滞后通常是微不足道的,因为每个线程在执行完毕之后,sum 方法最终还是能够准确反映所有更新的结果。
# LongAdder 使用场景
对于绝大多数应用场景来说,这种精度已经足够。LongAdder 提供了比 AtomicLong 更好的并发性能,同时在读取总计数时依然能够提供足够准确的结果。如果需要严格的精确性(例如金融交易系统中的金额计算),那么可能需要更严格的同步机制。然而,对于大多数统计和计数场景,LongAdder 是一个优秀的选择。
# LongAccumulator 和 LongAdder 区别
LongAdder:适用于简单的加法操作。 LongAccumulator:适用于自定义的累加操作。
也就是说LongAccumulator比LongAdder的灵活性更高。
LongAccumulator使用示例:
记录最大值
import java.util.concurrent.atomic.LongAccumulator;
public class TestA {
public static void main(String[] args) throws InterruptedException {
// 自定义累加函数为求最大值函数
LongAccumulator maxAccumulator = new LongAccumulator(Long::max, Long.MIN_VALUE);
// 模拟多个线程记录交易值
Thread t1 = new Thread(() -> {
long[] transactions = {28, 32, 36, 40, 44};
for (long transaction : transactions) {
maxAccumulator.accumulate(transaction);
}
});
Thread t2 = new Thread(() -> {
long[] transactions = {25, 30, 35, 40, 55};
for (long transaction : transactions) {
maxAccumulator.accumulate(transaction);
}
});
Thread t3 = new Thread(() -> {
long[] transactions = {22, 33, 44, 55, 66};
for (long transaction : transactions) {
maxAccumulator.accumulate(transaction);
}
});
t1.start();
t2.start();
t3.start();
t1.join();
t2.join();
t3.join();
// 获取最大的交易值
System.out.println("最大交易值: " + maxAccumulator.get()); // 最大交易值: 66
}
}
参考资料:
https://www.skjava.com/series/article/1618088484
https://pdai.tech/md/java/thread/java-thread-x-juc-AtomicInteger.html
https://tech.meituan.com/2019/02/14/talk-about-java-magic-class-unsafe.html
https://javabetter.cn/thread/Unsafe.html#_5%E3%80%81cas-%E6%93%8D%E4%BD%9C